Semantics
Let's give meaning to it all.
Table of Contents
Preliminaries: Natural Deduction §1
If you are unfamiliar with Natural Deduction and Gentzen-style proofs, please refer to the Wikipedia page on the topic. The sort story is that we refer to logical rules like this:
Which means that implies .
If we want multiple ways of reaching the conclusion, we can make more rules. For example, conjunction only requires one rule, both and has to be true but disjunction has two rules: either has to be true or has to be true.
In natural deduction, we build up syntactic objects which represents the truth of some event. We call them judgements. Many times you will see them written like , which is read: the context of , is true.
What are Semantics? §2
Today we are going to talk about semantics. Program semantics is about assigning meaning to programs. When we can talk about what a piece of syntax mean, it is easier to explain what a program does.
We are going to discuss some different approaches to writing down the semantics of a program. They all essentially turn programs syntax into mathematical logic.
Axiomatic Semantics §2.1
One of the first approaches invented to assign meaning to programs was Axiomatic Semantics. Here the meaning of the program is described by assigning precondition and postconditions to all statements in a program.
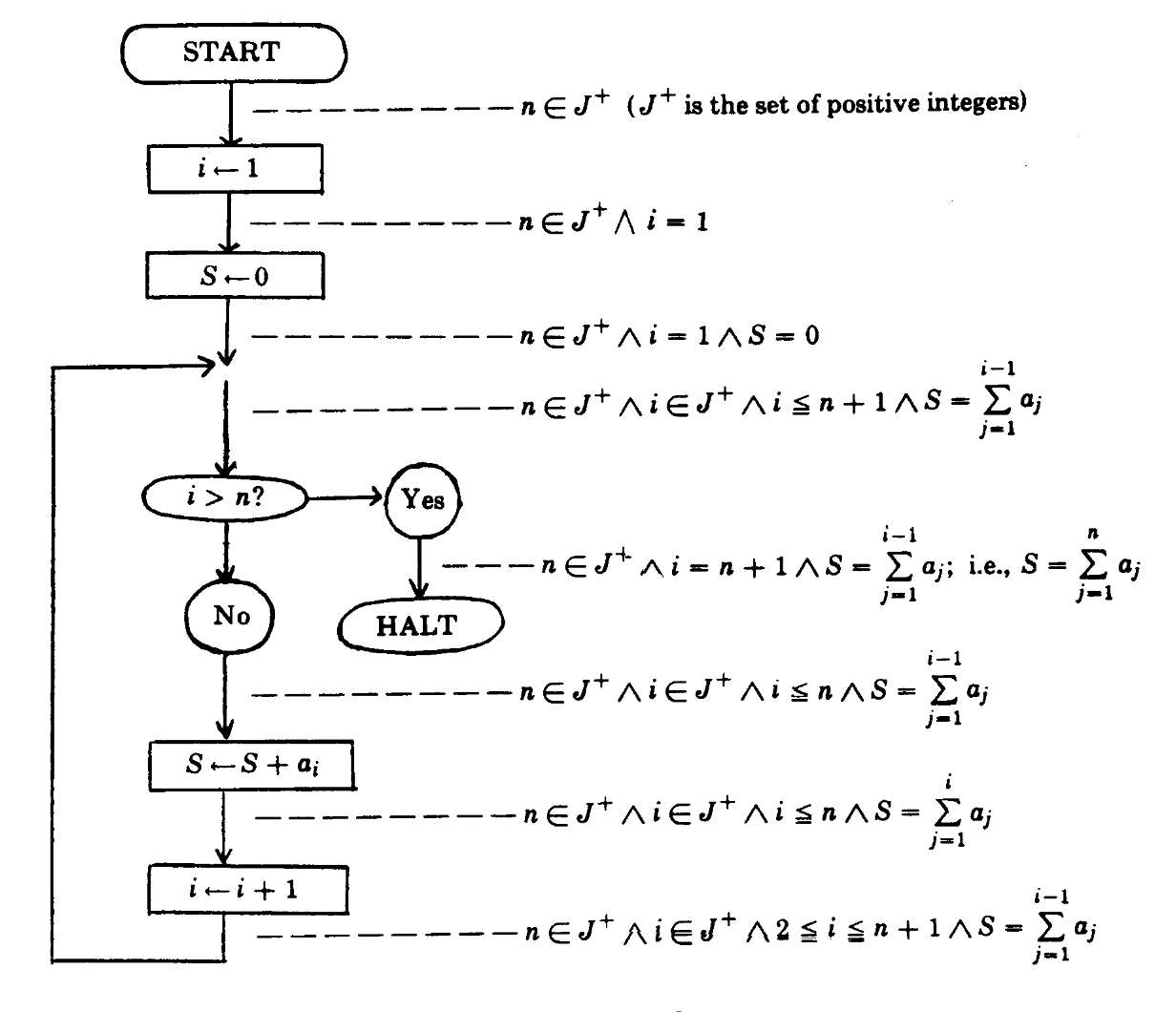
The flowchart from the original paper on semantics Assigning Meaning to Programs
by Robert W. Floyd. The program computes the sum of an array.
We can describe the semantics of a program by denoting three parts, the precondition , the program , and the postcondition , this is also called Hoare triplets.
A hoare triplet mean that if the world satisfies before executing then the world will satisfy after.
The great thing about this approach is that we can compose the proofs of correctness of parts of the program into a proof of total correctness. Assume the program , where is executed after . Then we can describe the correctness of , like so:
If you are unfamiliar with the syntax above, it is natural deduction see the section on natural deduction. Essentially it means that given , and , and that the postcondition of implies the precondition of , are all true, we can also prove that .
This approach is very effective at describing the meaning of specific programs. This makes it great for doing program verification, but is not used for program analysis in general.
Denotational Semantics §2.2
Another approach for writing down the semantics of the program is Denotational Semantics. The idea behind denotational semantics is to map the semantics of the program we want to analyse to something we know well. This can either be another programming language or math.
Consider a very simple expressional language called , which has addition, variables and natural numbers :
If want to give meaning to the program x + 5, then we can define a map from expressions to a function from a store to integers:
Here we explain that the semantic + means the same as mathematical operator , that variables are the same as looking up the variable in a store, and that numbers should just be read as natural numbers.
Now we can see that x + 5 can be calculated in the store , using normal math:
If you think that this looks exactly like functional programming, you would be right. It is also best at describing Expression-oriented programming languages.
Operational Semantics §2.3
Finally, we get to Operational Semantics, which is the semantic style we will focus on this semester. Operational semantics describes the semantic of a program as changes to a state. This makes it ideal for describing imperative languages like the JVM bytecode. Furthermore, the Structural Operational Semantics are defined exactly as you would write a interpreter, which is handy because you are going to write one.
The Structural Operational Semantics or Small Step Semantics are written as judgments of the type which means given the environment , the state of the program can be turned into .
The reason we call this approach the small step semantics is that we only execute a single operation at a time.
The Natural Operational Semantics or Big Step Semantics, are describing running the program until it halts. where is the final value of the program. Big step semantics often looks nicer than small step semantics, because it does not have to care about execution order.
Lambda Calculus
Consider the application rule of lambda calculus (see here and Lambda calculus - Wikipedia).
Here contains a mapping from variables to values, which we can update using the operation.
Essentially, it says that function application computes a in , if computes a closure , that computes a value , and that computes in the environment with set to . Compare this with the single step semantics:
Here we have three rules instead of one. First, in , we step the function , then, in we step the argument argument, finally we can insert the value into the closure . Notice, that we also have to keep track of the variables closed under the closure using the notation. We also need to add a closure evaluation rule:
Big Step semantics have the benefit of being easier to read, however, it has some big disadvantages, namely: we cannot reason about programs that run forever, and we cannot turn big step semantics into a working implementation. In contrast, small step semantics are easy to convert into an interpreter, and we can always recover the big step semantics from the operational semantics by simply applying the single step semantics until the program terminates with a value:
Transition System and Traces §2.4
Using our new found definition of single step semantics, we can define the meaning of a program as a Transition System:
A Transition System
A Transition system is a triplet where is the set of program states, is the transition relation (defined by the single step semantics) and are possible initial states.
A is the possible infinite sequence of states and operations of the program.
The meaning of a program is now the set of traces that it exhibit:
This is also called the Maximal Trace Semantics. We can now define properties, like does a program halt, using relatively well defined math:
But more about this next time.
Java Bytecode §3
Before we can start assign meaning to the JVM bytecode, we need to first understand what JVM bytecode is. There are many different instruction architectures, there are X86, ARM, RISCV, and so on. If you want to support them all you have to produce machine code for all of them. Instead Java wanted to provide a write once, run everywhere solution, and to this end they needed a virtual machine. A virtual machine is a piece of code which you can write for each platform, which all run the same virtual machine code. Actually, JVM stands for Java Virtual Machine.
When Java is compiled it gets compiled into a format known as JVM bytecode and placed in files with the .class extension. These files are called class files.
Inspect the class file
In the jpamb folder you should be able to run the following command to see the content of the target/classes/jpamb/cases/Simple.class file.
$ javap -cp target/classes -c jpamb.cases.SimpleIn each classfile, there is the name of the class, the fields of the class, and the methods of the class. And each method contains a list of instructions, which can be run. JVM bytecode is designed to be very easy to interpret, so it can be a little hard to read. In this course, we are going to use an intermediate language, which takes the two hundred and so instructions and turn them into 39, as well as doing some nice optimizations.
You should be able to find decompiled versions of each class file in the decompiled/ subfolder, in an easy to read JSON format (see codec here).
Inspect the Bytecode
First take a look at the decompiled code of the cases. First look at Simple.json. Now find the assertFalse method (it's listed in the methods). Now find the code.bytecode section, which should look like:
[
{ "field": { "class": "jpamb/cases/Simple", "name": "$assertionsDisabled", "type": "boolean" }, "offset": 0, "opr": "get", "static": true },
{ "condition": "ne", "offset": 3, "opr": "ifz", "target": 6 },
{ "class": "java/lang/AssertionError", "offset": 6, "opr": "new" },
{ "offset": 9, "opr": "dup", "words": 1 },
{ "access": "special", "method": { "args": [], "is_interface": false, "name": "<init>", "ref": { "kind": "class", "name": "java/lang/AssertionError" }, "returns": null }, "offset": 10, "opr": "invoke" },
{ "offset": 13, "opr": "throw" },
{ "offset": 14, "opr": "return", "type": null }
]Especially, notice the opr, it explains what operations to run:
| in# | opr | stack | description |
|---|---|---|---|
00 | get | [] | Get the assertionsDisabled boolean and put it on the stack |
01 | ifz | [bool] | if it is not equal to zero (false) jump to the 6th instruction (i.e. return) |
02 | new | [] | otherwise create a new AssertionError object. |
03 | dup | [ref] | dublicate the reference |
04 | invoke | [ref, ref] | call the init method on the AssertionErrror (consuming the top ref erence). |
05 | throw | [ref] | throw the assertion error. |
06 | return | [] | otherwise return. |
As a final help, have we build python classes for all the instruction used in the benchmark suite! You can see them here. To parse each bytecode you can either use the jpamb.jvm.Opcode.from_json function per instruction or use the jpamb.Suite.method_opcodes(methodid) to get the opcodes from an absolute method id.
Compare and contrast
Try to run the inspect command:
$ uv run jpamb inspect "jpamb.cases.Simple.assertBoolean:(Z)V"You can also try the other formats --format=repr (shows the python code), --format=real (shows the JVM memonic), and --format=json (shows the decompiled json).
Building a Bytecode Syntactic Analysis §3.1
Now you should be able to build a syntactic analysis over the bytecode:
Build a Bytecode Syntactic Analysis
Start by taking a look at the solutions/bytecoder.py. Then try to expand it to be more precise.
What are the Semantics of the JVM? §4
In this section, we are going to introduce some of the semantics of a limited JVM. It is incomplete and you would have to complete it on your own.
The goal of this section is to define the small step semantics of the JVM, and encode it in both math and in Python. You can follow along with the code in solutions/interpreter.py.
In math, we want to define judgments of , , or , where is the bytecode and is the state. And, in Python we want to define a function step, which given a state computes either a new state or a done
string.
def step(s : State) -> State | str:
...The Context and the Program Counter §4.1
As with all single step semantics rules, the JVM is run in a context. This context is the bytecode . For now we will define a simple operation which looks up the bytecode instruction at . is program counter, i.e., the name of the method and the offset in that method.
We use the following short hands:
To do this in Python you can should do something like this:
@dataclass
class PC:
method: jvm.AbsMethodID
offset: int
def __iadd__(self, delta):
self.offset += delta
return self
def __add__(self, delta):
return PC(self.method, self.offset + delta)
def __str__(self):
return f"{self.method}:{self.offset}"
@dataclass
class Bytecode:
suite: jpamb.Suite
methods: dict[jvm.AbsMethodID, list[jvm.Opcode]]
def __getitem__(self, pc: PC) -> jvm.Opcode:
try:
opcodes = self.methods[pc.method]
except KeyError:
opcodes = list(self.suite.method_opcodes(pc.method))
self.methods[pc.method] = opcodes
return opcodes[pc.offset]The Values, Operator Stack, and Locals. §4.2
The JVM is a stack based virtual machine, this means that instead of using named variables (registers) to store intermediate values, it instead uses an operator stack. Some values are stored in storage local to the methods called locals, which can be accessed using indices. Finally, the machine can also store information in global memory, which is referred to as the heap.
The values in (our interpretation of) JVM are dynamically typed, this means that every value caries around information about its type. There are two kinds of values, stack values and heap values .
The stack contains ints are signed 32 bit integers, floats are 32 bit floating point values (IEEE 754 Standard (JLS §1.7)), and references to the heap which are only 32 bits.
The heap can contain values from the stack, as well as bytes and chars that are 8 bits and 16 bits unsigned respectively, shorts are signed 16 bits, and arrays which a type and list of values, and objects which has a name and the values of the fields, which is a mapping from names to heap values.
In this course we'll not cover long and double as they are a pain in the *ss. Furthermore, we'll try to avoid inner classes and bootstrap methods as well.
Implementations of the values and types are stored in the jpamb.jvm.Value.
The stack is a list of values: . denote the empty stack and we add and remove elements from the end of the stack. A stack with the integers 1, 2, and 3, looks like this: . A simple implementation of this in python can be done like this:
@dataclass
class Stack[T]:
items: list[T]
def __bool__(self) -> bool:
return len(self.items) > 0
@classmethod
def empty(cls):
return cls([])
def peek(self) -> T:
return self.items[-1]
def pop(self) -> T:
return self.items.pop(-1)
def push(self, value):
self.items.append(value)
return self
def __str__(self):
if not self:
return "ϵ"
return "".join(f"{v}" for v in self.items)In the JVM saves local variables of type to a local array . This is were the inputs to the method goes and any data that should be saved on the method stack instead of in the heap. The local array is indexed normally .
In its simplest form, the state of the JVM is a triplet which we will call a frame, where is the locals, is the operator stack and is the program counter.
In Python, we would write:
@dataclass
class Frame:
locals: dict[int, jvm.Value]
stack: Stack[jvm.Value]
pc: PC
def __str__(self):
locals = ", ".join(f"{k}:{v}" for k, v in self.locals.items())
return f"<{{{locals}}}, {self.stack}, {self.pc}>"The Stepping Function §4.3
Most of our operations only operate on the frame, so we can already define our first simple SOS judgment like this:
Anticipating the definition of State in the next section, we define the stepping function, like so:
def step(state: State) -> State | str:
frame = state.frames.peek() # Get the current frame
match bc[frame.pc]:
case ...We are now ready for some examples. First we have the push operation :
Which we can encode in Python like this:
case jvm.Push(value=v):
frame.stack.push(v)
frame.pc += 1
return stateWe can also load values from the locals using the operation:
Which we can encode in Python like this:
case jvm.Load(type=jvm.Int(), index=n):
v = frame.locals[n]
assert v.type is jvm.Int()
frame.stack.push(v)
frame.pc += 1
return stateThe Call Stack, The Heap, and Terminating the Program §4.4
In the JVM methods are capable of calling other methods. To support this we need a stack of frames, or a call stack :
And now since we have multiple frames, we also need a way for the frames to share data. We call that the heap . And it is just mapping from memory locations to .
The state is now just a tuple of the heap and the call stack: . Which we can represent in Python like this:
@dataclass
class State:
heap: dict[int, jvm.Value]
frames: Stack[Frame]So now we have reached the correct definition of the stepping function, over the State.
We can use the operations we defined over frames, by lifting them into the state, by doing the frame operation on the top frame:
Our simplification of the JVM terminates when we exit from the last method, or we encounter an error. We do that with either an or an .
In Python, we can represent terminating with no error by simply returning "ok" if the stack is empty:
case jvm.Return(type=jvm.Int()):
v1 = frame.stack.pop()
state.frames.pop()
if state.frames:
frame = state.frames.peek()
frame.stack.push(v1)
frame.pc += 1
return state
else:
return "ok"One example of throwing an error is the divide operation:
Which can be translated into a single case match in Python. In the case we terminate with an error, we just return the corresponding string:
case jvm.Binary(type=jvm.Int(), operant=jvm.BinaryOpr.Div):
v2, v1 = frame.stack.pop(), frame.stack.pop()
assert v1.type is jvm.Int(), f"expected int, but got {v1}"
assert v2.type is jvm.Int(), f"expected int, but got {v2}"
if v2 == 0:
return "divide by zero"
frame.stack.push(jvm.Value.int(v1.value // v2.value))
frame.pc += 1
return stateWhat about the rest? §4.5
So this is a very limited definition of semantics the JVM, we have not covered threads or exceptions, and we probably won't in this course. But even with these restrictions there are still many undefined rules left.
It is your job to implement the rest of the instructions and build a working interpreter. To get started on this, we recommend you start small.
Write out dup as single step semantics
Write dup as single step semantic, given the definitions above. You can use the following resources:
jvm2json/CODEC.txt at kalhauge/jvm2json: the decompiled codec (search for
<ByteCodeInst>).Chapter 4. The class File Format: the class file format. And, finally
Chapter 6. The Java Virtual Machine Instruction Set: the official specification of each instruction.
Add dup to the case statement
Encode the dup instruction above in the solutions/interpreter.py file.
Finally, you should write an interpreter, which can interpret all the cases.
Write an Interpreter
Write an interpreter for the JVM, that given a method id and an input, prints the result on the last line.
$ uv run interpreter.py "jpamb.cases.Simple.assertInteger:(I)V" "(1)"
... alot ...
... of intermediate ...
... results ...
okAnd test it with:
$ uv run jpamb interpret -W --filter Simple interpreter.pyHere are some advice getting started:
Start small, one method at a time. You don't have to cover the entire language. Also you don't need a method stack or a heap for most of the cases — do them later.
It's okay to hack some things, like
getting
the$assertionsDisabledstatic field. You can assume that is always befalse.Print out the state to stderr at every step, this will help you debug.
Look at
solutions/interpreter.pyfor inspiration, or extend it.Use the
--stepwiseflag to run the last failed case next time.
Until next time!
Until next time, write the best analysis you can and upload the results to Autolab, and ponder the following:
Is analysing bytecode a semantic analysis?
Name some ways can you describe the semantics of a program?
What does it mean to interpret a piece of code?
Bibliography
Floyd, Robert W . (1993).
Assigning Meanings to Programs.
doi:10.1007/978-94-011-1793-7_4linkNielson, Hanne Riis; Nielson, Flemming (2007).
Semantics with Applications.
Plotkin, Gordon D (2004).
The origins of structural operational semantics.
doi:10.1016/j.jlap.2004.03.009link